- ElasticsearchとKibanaを立ち上げてみる
- LogstashでElasticsearchにログを取り込んでみる
- KibanaでElasticsearchのデータを可視化する
- FilebeatとLogstashでリモートのログを安全に転送する←イマココ
お正月やっていき企画のクライマックス(?)、リアルタイムリモートログ転送です。
ここまででELKの環境構築とログのパースまでを行い、既存のログをElasticsearchに投入、Kibanaで可視化できるようになりました。が、一方でリアルタイムでのログ収集は実現できていません。
世間ではFluentdと連携させることも多いと思いますが、今回はFilebeatとLogstashを組み合わせてリアルタイムログ転送を実現していきます。
概要
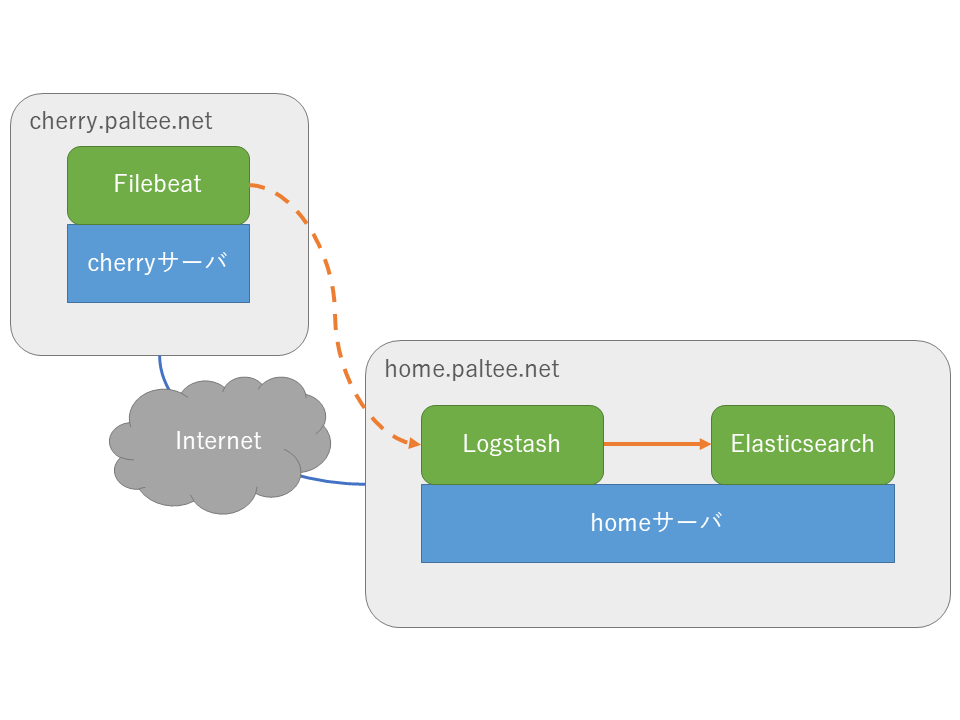
ロギングの題材としているアプリケーションはVPS上で動いている一方で、Elasticsearchは自宅のサーバで動作しています(お金がないので)。
今回はVPS(以後cherryサーバ)側にFilebeatを配置し、自宅(以後homeサーバ)のLogstashで待ち受けます。
イメージとしてはこんな感じ
環境構築
cherryサーバ
公式ドキュメントを見ながらFilebeatを直接インストールします。
homeサーバ
LogstashはElasticsearchと紐づいたサービスとして動かしておきたいので、以前の記事で作成したdocker-compose.ymlに新たなサービスとして追記します。
logstash:
image: docker.elastic.co/logstash/logstash:7.5.1
ports:
- 5044:5044
volumes:
- ./logstash:/usr/share/logstash/pipeline
environment:
- pipeline.workers=1ここではSidekiqのログをaggregateフィルタで取り扱う都合上pipeline.workers=1を指定しています。
また、設定ファイルはlogstashディレクトリに保存したものをコンテナに読み込ませるのでvolumesでマウントしています。
ログ転送設定
cherryサーバ
/etc/filebeat/filebeat.ymlを以下のように設定します。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.circlesearch.ltsv.log*
exclude_files: ['.gz$']
fields:
type: nginx
app: circlesearch
output.logstash:
hosts: ["home.paltee.net:5044"]Logstashは単一ポートでログを待ち受けるので、ログの種類によって適切なインデックスに振り分けてデータを投入する必要があります。したがって、転送元のFilebeatではfieldsにパラメータを付与してログを転送しておきます。
調べてみるとgzipで圧縮されたファイルは処理できないらしいので除外してあります。issueは2016年に立てられてますが丸3年動きはないみたいですね……。
foo.log.1)もinputの対象にすることでちゃんとローテーションされてることを検知できるらしいです。具体的にはローテーションされた時点でのinodeの変化で検出しているそう。ということでログ収集の対象となるファイルはワイルドカードで指定します。
homeサーバ
logstash.confはdocker-composeの設定ディレクトリ内に作ったlogstashディレクトリの中に作成します。
input {
beats {
port => 5044
}
}
filter {
if [fields][type] == "nginx" {
# nginx用の設定
}
if [fields][type] == "sidekiq" {
# Sidekiq用の設定
}
}
output {
elasticsearch {
hosts => ["es:9200"]
index => "%{[fields][app]}-production-%{[fields][type]}-%{+YYYY.MM.dd}"
}
}
inputセクションはシンプルにbeatsプラグインへポート番号を渡せばOKです。
filterには以前の記事と同じくログをパースする設定を記述しますが、ログの種類によって処理を振り分けられるようにFilebeatで付与したフィールドで分岐させます。
outputも以前と同様に送信先としてElasticsearchを指定しますが、インデックス名をFilebeatで付与したフィールドを使って決定しておきます。さもなければすべて同じプレフィックスのインデックスにデータが記録されてしまいます。
ここまででログのリアルタイム転送が実現できるようになりました。
TLSで暗号化とクライアント認証をする
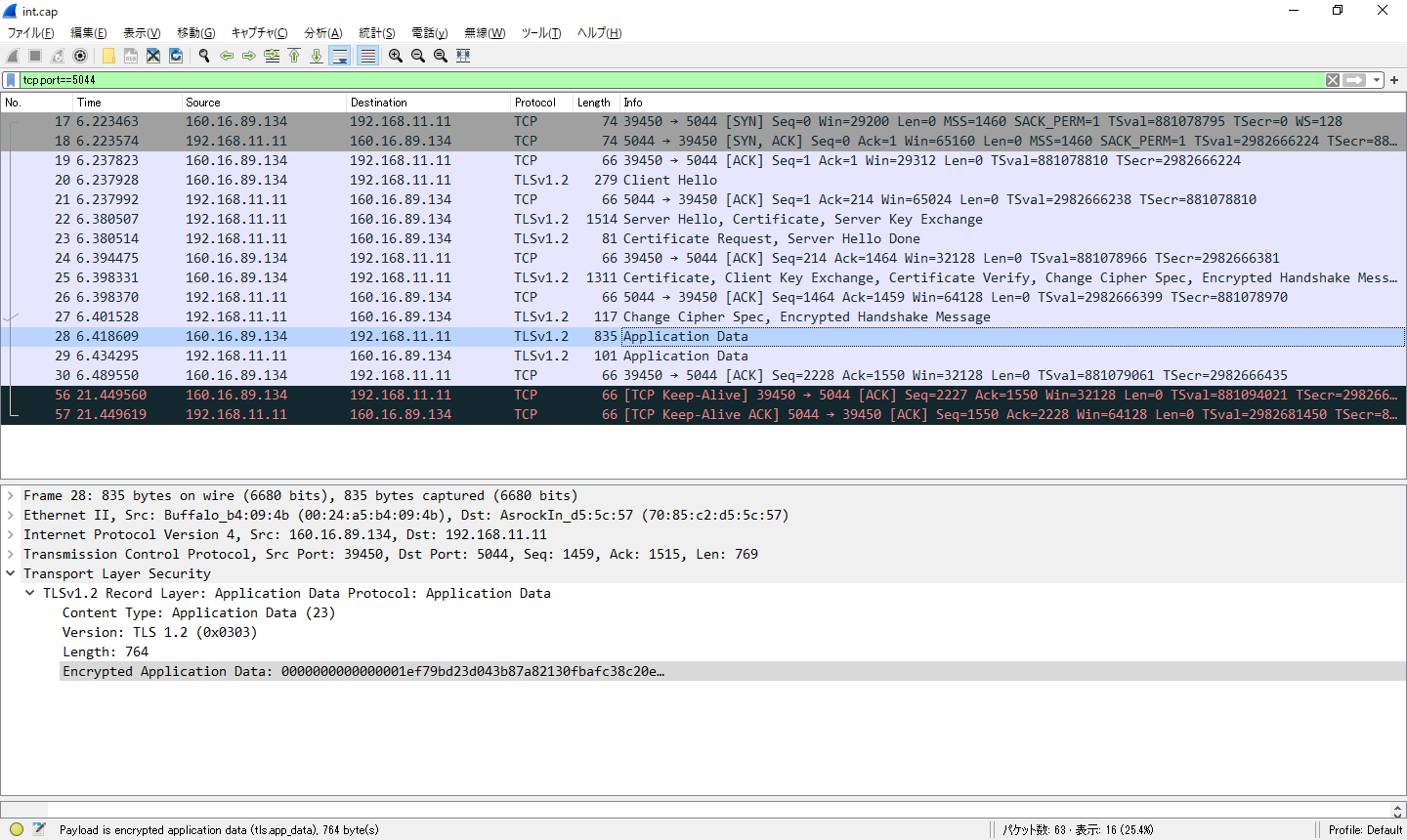
さて、ここで一度Filebeatをローカル環境にインストールした上で、FilebeatとLogstashを同一ホスト上で起動してみます。
動作中にホストを流れるパケットをキャプチャした結果がこちらです。

なんということでしょう。Filebeatの手によって送られるログデータが丸見えとなっています。
当然、このままインターネットを介してログを転送すれば第三者が覗き放題となります。
LogstashとFilebeatはデジタル証明書を利用して通信できるようになっているので、今回はこれを利用してメッセージの暗号化と通信相手の識別ができるようにします。
証明書の作成
それぞれのサーバで証明書(公開鍵)と対応した秘密鍵を生成していきます。真面目にやろうとすると認証局を立てて署名した証明書を作る必要がありますが、今回は通信路の暗号化とクライアントの認証が達成できればいいので自己署名なオレオレ証明書で済ませます。
opensslでは証明書署名要求を生成するためにreqコマンドを使いますが、ここに-x509オプションを指定すると自己署名証明書を生成します。
cherryサーバではFilebeatの設定フォルダにsslディレクトリを作成してcherry.crtという名前で証明書を生成します。
# cd /etc/filebeat
# mkdir ssl && cd ssl
# openssl req -x509 -batch -nodes -newkey rsa:2048 -keyout priv.key -out cherry.crt -days $((365 * 20))homeサーバはdocker-composeの設定フォルダにsslディレクトリを作成してhome.crtという名前で証明書を生成します。
$ mkdir ssl && cd ssl
$ openssl req -x509 -nodes -newkey rsa:2048 -keyout priv.key -out home.crt -days $((365 * 20))証明書の設定
それぞれのホストで証明書を作成したら、証明書のみを互いのホストのsslディレクトリにコピーします。各ホストにはpriv.key, cherry.crt, home.crtの3ファイルが存在していることになります。
homeサーバのLogstashはコンテナ上で動かしているので、証明書をコンテナから参照できるようにdocker-compose.ymlを以下のように変更しておきます。
(中略)
logstash:
volumes:
- ./logstash:/usr/share/logstash/pipeline
- ./ssl:/opt/ssl # 追記さらにlogstash/logstash.ymlのinputセクションを以下のように変更します。
input {
beats {
port => 5044
ssl => true
ssl_certificate_authorities => ["/opt/ssl/cherry.crt"]
ssl_certificate => "/opt/ssl/home.crt"
ssl_key => "/opt/ssl/priv.key"
}
}cherryサーバではfilebeat.ymlのoutputを以下の通り変更します。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.circlesearch.ltsv.log*
fields:
type: nginx
app: circlesearch
output.logstash:
hosts: ["home.paltee.net:5044"]
ssl:
enabled: true
certificate_authorities: ["/etc/filebeat/ssl/home.crt"]
certificate: "/etc/filebeat/ssl/cert.crt"
key: "/etc/filebeat/ssl/priv.key"続いてFilebeatとLogstashを立ち上げ、KibanaのDiscoverタブを開いて時間の範囲をLast 15 minutesあたりにしてみます。正しくデータが転送できていれば直近のレコードが表示されるはずです。
パケットをキャプチャしてもTLSで通信が行われていることがわかります。
イベントの重複を防ぐ
これで過去のログと一緒にデータの可視化もできるようになりますが、何も考えないまま投入すると登録済みのレコードと重複してしまう場合があります。
そこで、レコードごとにユニークな識別子(ID)を割り振ることを考えます。もしもデータを追加する際にそのレコードと同じ識別子が存在していれば、上書き操作を行うことでデータを二重に登録することを防ぐことができます。
識別子の生成方法
この識別子の生成方法としては主にUUIDを用いる方法とハッシュ関数を用いる方法の2通りが存在します。
UUIDを利用する場合にはイベントの生成元で一意なIDを生成してから信頼性のない経路に送信する必要があります。今回の場合ではログの転送元であるリモートサーバのFilebeatに相当する部分でIDを割り当てることとなります。
一方ハッシュ関数を用いる場合はレコードの内容に対してIDが紐づくため、イベントを欠落なく転送できていれば任意の場所でIDを生成することができます。したがって、今回のログの送信先であるLogstashでもIDを生成できることとなります。
今回は一連のログの加工をLogstash上で行っているので、後者のハッシュ関数を用いたID生成をLogstashで行います。
IDを生成することでデータを二重に登録することを防げる一方で、登録ごとにIDを探索する必要が出てくるためデータ量が増加した際に動作が遅くなる可能性があります。
しかしElasticsearchはソートされた識別子に対しては効率的に探索を行うことができるので、レコードの時刻とダイジェストに基づいて識別子を生成してやればパフォーマンスの低下を防ぎながらイベントの重複を防ぐことができます。加えて、時刻とログのハッシュを結合することで識別子の衝突可能性は無視できるレベルまで小さくなります。
Logstashの設定
filter内の実際の設定は以下のようになります。
fingerprint {
source => "message"
target => "[@metadata][fingerprint]"
method => "MD5"
}
ruby {
code => "event.set('[@metadata][tsprefix]', event.get('@timestamp').to_i.to_s(16))"
}まずfilterの中でfingerprintフィルタを呼び出し、ログの内容に対応するハッシュを算出します。
続いてrubyフィルタを使ってイベントの時刻を16進数に変換してメタデータに格納します。
最後に以下のようにしてelasticsearch output pluginのdocument_idへ算出したハッシュと時刻を結合したIDを割り振ります。
elasticsearch {
document_id => "%{[@metadata][tsprefix]}%{[@metadata][fingerprint]}"
}実際に実行すると16進数で長さ40のIDが5ba5f7af68211c4d022bc93af0b46c240530ce03のような形で決定されます。先頭の8文字はタイムスタンプで残りがMD5のダイジェスト値となります。
どうせ生きてないでしょ
[1] pry(main)> Time.at("ffffffff".to_i(16))
=> 2106-02-07 15:28:15 +0900
[2] pry(main)> Time.at("fffffffff".to_i(16))
=> 4147-08-20 16:32:15 +0900まとめ
Logstashを使って手作業でデータを投入していたのに対して、リアルタイムで安全にログを転送することができるようになりました。
割と久々にデジタル証明書の仕組みを復習できたので良かったです。