前回の記事ではdocker-composeを使ってElasticsearchとKibanaを立ち上げました。
今回はLogstashを使ってnginxとSidekiqのログファイルをElasticsearchに投入してみます。
- ElasticsearchとKibanaを立ち上げてみる
- FilebeatとLogstashでリモートのログを安全に転送する←イマココ
- KibanaでElasticsearchのデータを可視化する
- FilebeatとLogstashでリモートのログを安全に転送する
Logstashのインストール
Logstashではログを取り込む設定をちまちま変えつつ検証したりしていくので、直接インストールしてしまいます。
公式ドキュメントの通りに進めていくと、実行ファイルは/usr/share/logstash/bin/logstashに入ります。
コマンドラインで実行する場合、logstashユーザの領域を読み書きする権限がないと動かないので、sudo -u logstash /usr/share/logstash/bin/logstashと叩く必要があります。
さらにLogstashをシステム上でサービスとして立ち上げる場合は競合してしまうため、動作チェックとして動かすならば以下のように作業ディレクトリを掘ってpath.dataに指定したほうが無難です。自分のパーミッションが設定されたディレクトリであればsudoは不要になります。
$ mkdir /tmp/logstash
$ /usr/share/logstash/bin/logstash -f logstash.conf --path.data /tmp/logstash/nginxのログ設定
ログを加工しやすくするために、nginxのログ設定をltsv形式に変更しておきます。
まずは新たなログ形式をnginx.confのhttpディレクティブに定義します。
log_format ltsv "time:$time_local"
"\thost:$remote_addr"
"\tforwardedfor:$http_x_forwarded_for"
"\treq:$request"
"\tmethod:$request_method"
"\turi:$request_uri"
"\tstatus:$status"
"\tsize:$body_bytes_sent"
"\treferer:$http_referer"
"\tua:$http_user_agent"
"\treqtime:$request_time"
"\truntime:$upstream_http_x_runtime"
"\tapptime:$upstream_response_time"
"\tcache:$upstream_http_x_cache"
"\tvhost:$host";続いてserverディレクティブでログの出力先をaccess_log /var/log/nginx/access.ltsv.log ltsv;と指定します。
nginxを再起動すれば新しくファイルが作成され、以下のようにログが出力されていきます。
time:04/Jan/2020:21:04:24 +0900 host:115.165.99.82 forwardedfor:- req:GET / HTTP/2.0 status:200 size:3055 referer:https://t.co/YvT7PSZeSF?amp=1 ua:Mozilla/5.0 (Linux; Android 7.1.1; HTV33) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.93 Mobile Safari/537.36 reqtime:0.008 cache:- runtime:0.005956 vhost:circlesearch.paltee.net
time:04/Jan/2020:21:47:08 +0900 host:40.77.167.46 forwardedfor:- req:GET / HTTP/1.1 method:GET uri:/ status:200 size:3070 referer:- ua:Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) reqtime:0.013 runtime:0.012430 apptime:0.016 cache:- vhost:circlesearch.paltee.net
time:04/Jan/2020:22:28:39 +0900 host:60.47.179.60 forwardedfor:- req:GET /api/v1/events HTTP/2.0 method:GET uri:/api/v1/events status:200 size:13 referer:- ua:okhttp/3.10.0 reqtime:0.007 runtime:0.006602 apptime:0.004 cache:- vhost:circlesearch.paltee.netログのパース
Logstashの設定ファイルは大きくinput, filter, outputの3つのセクションから構成されます。
input, outputはその名の通り入出力を指定しますが、filterでは様々なフィルタプラグインを利用して受け取ったログを整形・変換していきます。
nginx
早速ltsv形式のnginxログをパースしてみます。とりあえずログをコピーして作業用ディレクトリに置いておきましょう。
とりあえず分割
ltsv形式のログなので、以下のようにkvフィルタを使えば文字の羅列からキーと値のペアにはすぐに変換できます。field_splitオプションにはフィールドを区切る文字としてタブを、value_splitオプションにはキーと値を区切る文字を指定します。
また、ここではinputとoutputに標準入出力を指定しています。
ログを正しくパースできることを確認した後、inputをログファイルに、outputをElasticsearchに向けることで実際にログの集約が可能になります。
input {
stdin { }
}
filter {
kv {
field_split => "\t"
value_split => ":"
}
}
output {
stdout {
codec => rubydebug
}
}
これをlogstash_nginx.confとして保存し、以下のように実行してみます。
cat access.ltsv.log | head -n 3 | /usr/bin/share/logstash/bin/logstash -f logstash_nginx.conf --path.data /tmp/logstash | less -Rするとこんな感じの結果に。
{
"time" => "04/Jan/2020:21:04:24 +0900",
"reqtime" => "0.008",
"@version" => "1",
"cache" => "-",
"@timestamp" => 2020-01-05T12:56:19.792Z,
"runtime" => "0.005956",
"referer" => "https://t.co/YvT7PSZeSF?amp=1",
"status" => "200",
"uri" => "/",
"vhost" => "circlesearch.paltee.net",
"req" => "GET / HTTP/2.0",
"message" => "time:04/Jan/2020:21:04:24 +0900\thost:115.165.99.82\tforwardedfor:-\treq:GET / HTTP/2.0\tstatus:200\tsize:3055\treferer:https://t.co/YvT7PSZeSF?amp=1\tua:Mozilla/5.0 (Linux; Android 7.1.1; HTV33) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.93 Mobile Safari/537.36\treqtime:0.008\tcache:-\truntime:0.005956\tvhost:circlesearch.paltee.net",
"forwardedfor" => "-",
"method" => "GET",
"host" => "115.165.99.82",
"size" => "3055",
"ua" => "Mozilla/5.0 (Linux; Android 7.1.1; HTV33) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.93 Mobile Safari/537.36"
}
{
"time" => "04/Jan/2020:21:47:08 +0900",
"reqtime" => "0.013",
"@version" => "1",
"cache" => "-",
"@timestamp" => 2020-01-05T12:56:19.841Z,
"runtime" => "0.012430",
"referer" => "-",
"status" => "200",
"uri" => "/",
"vhost" => "circlesearch.paltee.net",
"req" => "GET / HTTP/1.1",
"message" => "time:04/Jan/2020:21:47:08 +0900\thost:40.77.167.46\tforwardedfor:-\treq:GET / HTTP/1.1\tmethod:GET\turi:/\tstatus:200\tsize:3070\treferer:-\tua:Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)\treqtime:0.013\truntime:0.012430\tapptime:0.016\tcache:-\tvhost:circlesearch.paltee.net",
"forwardedfor" => "-",
"method" => "GET",
"apptime" => "0.016",
"host" => "40.77.167.46",
"size" => "3070",
"ua" => "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
}
{
"time" => "04/Jan/2020:22:28:39 +0900",
"reqtime" => "0.007",
"@version" => "1",
"cache" => "-",
"@timestamp" => 2020-01-05T12:56:19.842Z,
"runtime" => "0.006602",
"referer" => "-",
"status" => "200",
"uri" => "/api/v1/events",
"vhost" => "circlesearch.paltee.net",
"req" => "GET /api/v1/events HTTP/2.0",
"message" => "time:04/Jan/2020:22:28:39 +0900\thost:60.47.179.60\tforwardedfor:-\treq:GET /api/v1/events HTTP/2.0\tmethod:GET\turi:/api/v1/events\tstatus:200\tsize:13\treferer:-\tua:okhttp/3.10.0\treqtime:0.007\truntime:0.006602\tapptime:0.004\tcache:-\tvhost:circlesearch.paltee.net",
"forwardedfor" => "-",
"method" => "GET",
"apptime" => "0.004",
"host" => "60.47.179.60",
"size" => "13",
"ua" => "okhttp/3.10.0"
}
messageフィールドに1つのレコードが入り、各カラムはそれぞれフィールドに振り分けられていることがわかります。一見これでOKなように見えますが、よく見るとsizeやreqtimeといった数値データとtimeフィールドが文字列として扱われていることがわかります。
このままElasticsearchに投入すると、可視化時に肝心のグラフ化ができなくなったりして不便なのでもう少し手を加えます。
データ型の変換
まず数値データであるフィールドの型を以下のmutateフィルタによって明示的に指定します。
mutate {
convert => {
"size" => "integer"
"status" => "integer"
"reqtime" => "float"
"apptime" => "float"
"runtime" => "float"
}
}また、日付のフィールドはdateプラグインで以下のように変換します。ここではtimeフィールドに対してフォーマット"dd/MMM/yyyy:HH:mm:ss Z"に従い変換して得られる時刻を再びtimeフィールドに戻します。
date {
match => ["time", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "time"
}これらのフィルタを先ほどの設定ファイルのfilterの最後に追記します。
再びLogstashを実行すると以下のような出力となり、数値データとtimeフィールドが正しくパースされていることがわかります。これらのフィールドを用いてKibana上でグラフの作成もできるようになりました。
{
"uri" => "/api/v1/events",
"vhost" => "circlesearch.paltee.net",
"forwardedfor" => "-",
"time" => 2020-01-04T13:28:39.000Z,
"referer" => "-",
"host" => "60.47.179.60",
"ua" => "okhttp/3.10.0",
"@version" => "1",
"apptime" => 0.004,
"cache" => "-",
"@timestamp" => 2020-01-05T13:41:18.962Z,
"req" => "GET /api/v1/events HTTP/2.0",
"method" => "GET",
"message" => "time:04/Jan/2020:22:28:39 +0900\thost:60.47.179.60\tforwardedfor:-\treq:GET /api/v1/events HTTP/2.0\tmethod:GET\turi:/api/v1/events\tstatus:200\tsize:13\treferer:-\tua:okhttp/3.10.0\treqtime:0.007\truntime:0.006602\tapptime:0.004\tcache:-\tvhost:circlesearch.paltee.net",
"reqtime" => 0.007,
"runtime" => 0.006602,
"size" => 13,
"status" => 200
}続いてこのログをElasticsearchに取り込みます。Elasticsearchにデータを投入する場合はElasticsearch output pluginに送信先のElasticsearchホストとインデックス名を渡せばOKです。
前回の記事の通りElasticsearchはlocalhostの9200番ポートで待ち受けているので、outputを以下のように書き換えLogstashを実行します。正しく実行できればエラーなくLogstashは終了します。
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "nginx-access-%{+YYYY.MM.dd}"
}
}Sidekiq
今回ログを記録するアプリケーションではSidekiqも使っており、各ジョブについてもログをまとめることにしました。
Sidekiqのログはlog/sidekiq.logにこんな感じで出力されます。
2019-12-27T13:29:18.437Z 19095 TID-gq8zsrb8g INFO: Booting Sidekiq 4.2.10 with redis options {:url=>"redis://localhost:6379", :namespace=>"sidekiq_Circlesearch_production"}
set_default_options has been deprecated, use set_options
2019-12-27T13:29:19.058Z 19095 TID-gq8zsrb8g INFO: Running in ruby 2.6.2p47 (2019-03-13 revision 67232) [x86_64-linux]
2019-12-27T13:29:19.059Z 19095 TID-gq8zsrb8g INFO: See LICENSE and the LGPL-3.0 for licensing details.
2019-12-27T13:29:19.059Z 19095 TID-gq8zsrb8g INFO: Upgrade to Sidekiq Pro for more features and support: http://sidekiq.org
2019-12-27T13:29:21.164Z 19095 TID-gq908zgnw UserUpdateJob JID-8e3de59d5440c6dc9873a5d0 INFO: start
2019-12-27T13:29:23.507Z 19095 TID-gq908zgnw UserUpdateJob JID-8e3de59d5440c6dc9873a5d0 INFO: done: 2.343 sec
2019-12-28T15:45:39.129Z 19095 TID-gq908zgzk UserUpdateJob JID-1b8a11a791365774b292477b INFO: start
2019-12-28T15:45:39.252Z 19095 TID-gq908zgzk UserUpdateJob JID-1b8a11a791365774b292477b INFO: fail: 0.123 sec
2019-12-28T15:45:39.252Z 19095 TID-gq908zgzk UserUpdateJob JID-1b8a11a791365774b292477b INFO: Adding dead ActiveJob::QueueAdapters::SidekiqAdapter::JobWrapper job 1b8a11a791365774b292477bnginxのログの場合はltsv形式での出力としたためタブで分割すれば基本的な整形が終わりましたが、今回は加工用の設定がされていないべた書きのログを取り扱うため、よしなに設定を作っていく必要があります。
正規表現で引っかける
ここで登場するのがgrokフィルタで、正規表現を使ってログからデータをフィールドに切り出すことができます。
grokフィルタのmatchオプションにはパース対象のフィールド(何も手を付けていないのでレコードが入っているmessageフィールド)とマッチさせる正規表現を記述します。今回はこんな感じに。
grok {
match => [ "message", "%{TIMESTAMP_ISO8601:time} %{INT:pid} TID-%{NOTSPACE:tid} %{NOTSPACE:job} JID-%{NOTSPACE:jid} %{LOGLEVEL:loglevel}: (?<state>start|done|fail)(: %{NUMBER:duration} sec)?" ]
}matchオプションで指定する正規表現では、よく使うパターンはあらかじめ定数として宣言されているので簡単に利用できます。これらのパターンは公式のGitHubで確認でき、利用する場合は%{パターン名:フィールド名}と記述します。Sidekiqログの行の最初は時刻なので、ここではtimeという名前のフィールドとしてISO8601形式のフォーマットでキャプチャするよう指定しています。
定数パターンを先のフォーマットに沿って作成したファイルを含むディレクトリをgrokフィルタのpatterns_dirで指定することで、パターンを自分で構築することも可能です。そこまで大げさなものにならない場合はPCREで用いられる名前付きキャプチャを記述することでフィールドに切り出してくれます。ここでは各行が示す状態を(?<state>start|done|fail)で引っ掛けてstateフィールドに切り出しています。
そのほかジョブ終了時に出力される実行時間をdurationフィールドとしてキャプチャする設定も入れていますが、ジョブ開始時には出力されずパターンにマッチできなくなるため()?で囲っています。
またgrokで指定するパターンはあくまでも文字列の並びを表現したものにすぎないため、データ型の変換はdateフィルタやmutateフィルタで明示的に行わなければならない点に注意が必要です。
次にこれらのログをジョブ単位で集約していきます。
aggregateフィルタのtask_idにイベントを識別するユニークな文字列を指定することで、この値ごとに集約処理を行うことができます。処理の分岐はifを用いて行います。
まずジョブの開始イベントでは以下のようにしてジョブの開始時刻を記録しておきます。
if [state] == "start" {
aggregate {
task_id => "%{jid}"
code => "map['started_at'] = event.get('time')"
}
}codeオプションにはRubyのソースを記述しますが、変数mapがtask_id単位で割り当てられるハッシュとして参照できるようになっています。
ここではstarted_atとしてレコードの時刻をmapへ一時的に保存しています。
続いてジョブの終了イベントで先ほど記録した開始時刻をマージします。集約の終了となるイベントではend_of_taskオプションをtrueに指定しておきます。
if [state] == "done" or [state] == "fail" {
aggregate {
task_id => "%{jid}"
code => "event.set('started_at', map['started_at']);"
end_of_task => true
}
}ここまでの設定に合わせて、忘れずにdateプラグインでtimeフィールドを時刻型へ、またdurationはfloat型に変換しておきます。timeフィールドはaggregateフィルタを通す時点で時刻型にしておく必要があるため、aggregateフィルタよりも手前に記述します。
最終的な設定は以下のようになりました。
input {
stdin { }
}
filter {
grok {
match => [ "message", "%{TIMESTAMP_ISO8601:time} %{INT:pid} TID-%{NOTSPACE:tid} %{NOTSPACE:job} JID-%{NOTSPACE:jid} %{LOGLEVEL:loglevel}: (?<state>start|done|fail)(: %{NUMBER:duration} sec)?" ]
}
if "_grokparsefailure" in [tags] {
drop { } # skip when parsing failed
}
date {
match => [ "time", "ISO8601" ]
target => "time"
}
if [state] == "start" {
aggregate {
task_id => "%{tid}-%{jid}"
code => "map['started_at'] = event.get('time')"
}
drop { }
}
if [state] == "done" or [state] == "fail" {
aggregate {
task_id => "%{tid}-%{jid}"
code => "event.set('started_at', map['started_at']);"
end_of_task => true
}
mutate {
gsub => [ "state", "done", "success" ]
}
mutate {
rename => {
"state" => "result"
"time" => "finished_at"
}
}
mutate {
convert => {
"duration" => "float"
}
}
}
}
output {
stdout { codec => rubydebug }
}
aggregateフィルタではレコードを集約してもイベントはまとめられないようなので、stateがstartであるジョブ開始イベントは時刻のみをmapに記録し、dropフィルタで破棄しています。
またそもそもパターンにマッチしないレコード(Sidekiqの起動メッセージなど)は、タグに_grokparsefailureが追加されるのでこれに基づき破棄します。これを忘れると各行が1つのログとして取り込まれるため、時刻ごとにまとめたりしてグラフを作ると大変なことになります。
その他、ジョブ終了イベントのtimeフィールドはfinished_atに、stateはresultにフィールド名を変更し、resultフィールドの値doneはsuccessに置換しています。
この設定に基づいてLogstashを実行すると以下のような出力が得られます。
{
"host" => "userver",
"pid" => "19095",
"job" => "UserUpdateJob",
"duration" => 2.343,
"jid" => "8e3de59d5440c6dc9873a5d0",
"finished_at" => 2019-12-27T13:29:23.507Z,
"@version" => "1",
"@timestamp" => 2020-01-05T13:59:48.789Z,
"result" => "success",
"started_at" => 2019-12-27T13:29:21.164Z,
"message" => "2019-12-27T13:29:23.507Z 19095 TID-gq908zgnw UserUpdateJob JID-8e3de59d5440c6dc9873a5d0 INFO: done: 2.343 sec",
"tid" => "gq908zgnw",
"loglevel" => "INFO"
}
{
"host" => "userver",
"pid" => "19095",
"job" => "UserUpdateJob",
"duration" => 0.123,
"jid" => "1b8a11a791365774b292477b",
"finished_at" => 2019-12-28T15:45:39.252Z,
"@version" => "1",
"@timestamp" => 2020-01-05T13:59:48.789Z,
"result" => "fail",
"started_at" => 2019-12-28T15:45:39.129Z,
"message" => "2019-12-28T15:45:39.252Z 19095 TID-gq908zgzk UserUpdateJob JID-1b8a11a791365774b292477b INFO: fail: 0.123 sec",
"tid" => "gq908zgzk",
"loglevel" => "INFO"
}Sidekiqのログからジョブの実行情報だけを抽出し、ジョブ単位でイベントが集約できていることがわかります。
正しく動作することが確認出来たらnginxのログと同様にElasticsearchへ投入します。
Kibana上でログを確認する
ログがElasticsearchに取り込まれたことを確認するためにKibana上でデータを見てみます。
KibanaでElasticsearchのデータを利用するにはまずインデックスパターンを作成する必要があるので、KibanaのダッシュボードからDiscoverタブを開きます。
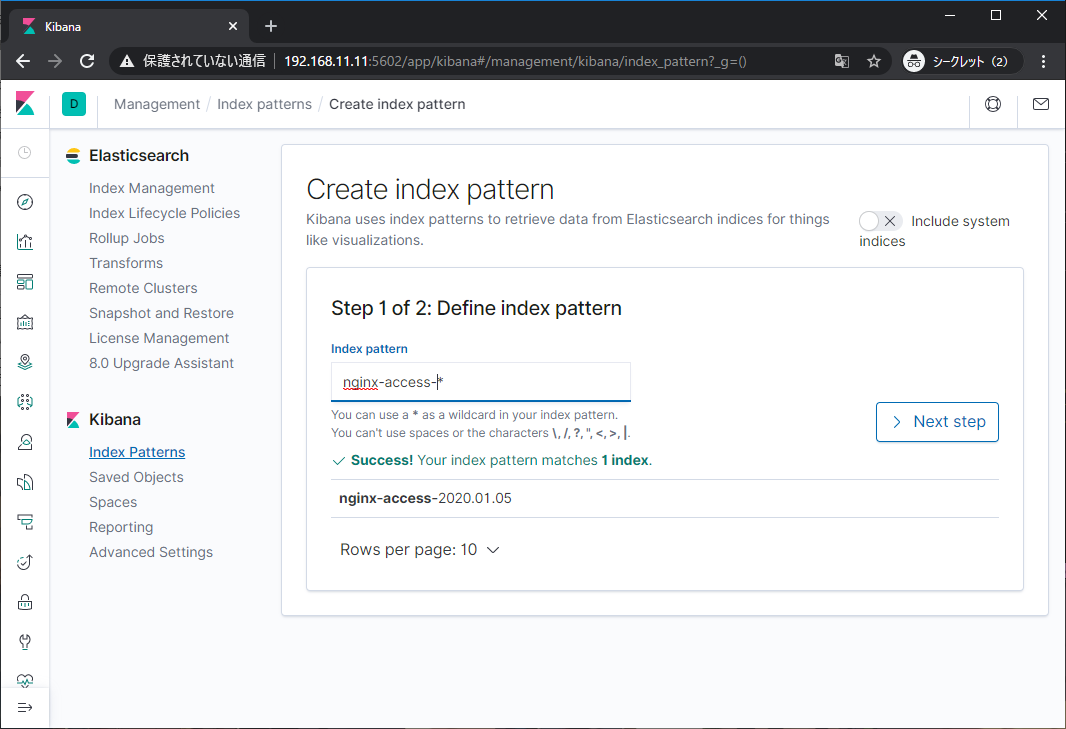
投入したデータのインデックス(nginx-access-2020.01.05)が表示されているはずなので、これにマッチするパターンを入力します。
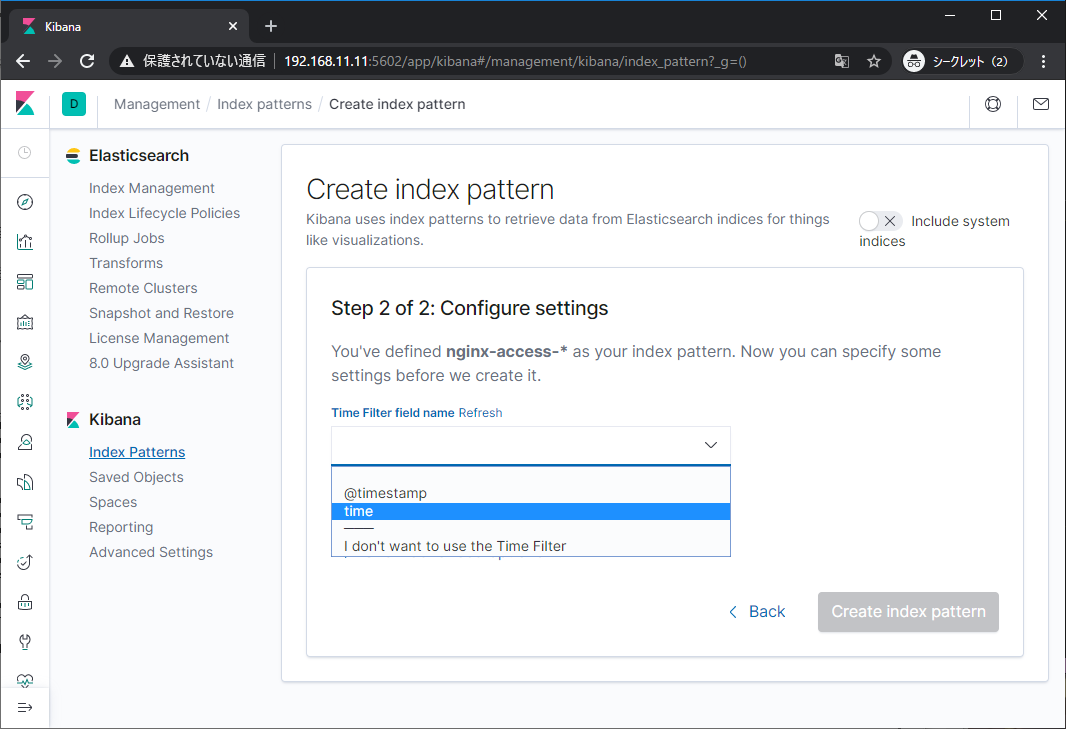
次に時刻のフィールドを指定します。これにより時間のフィルタが利用できるようになります。
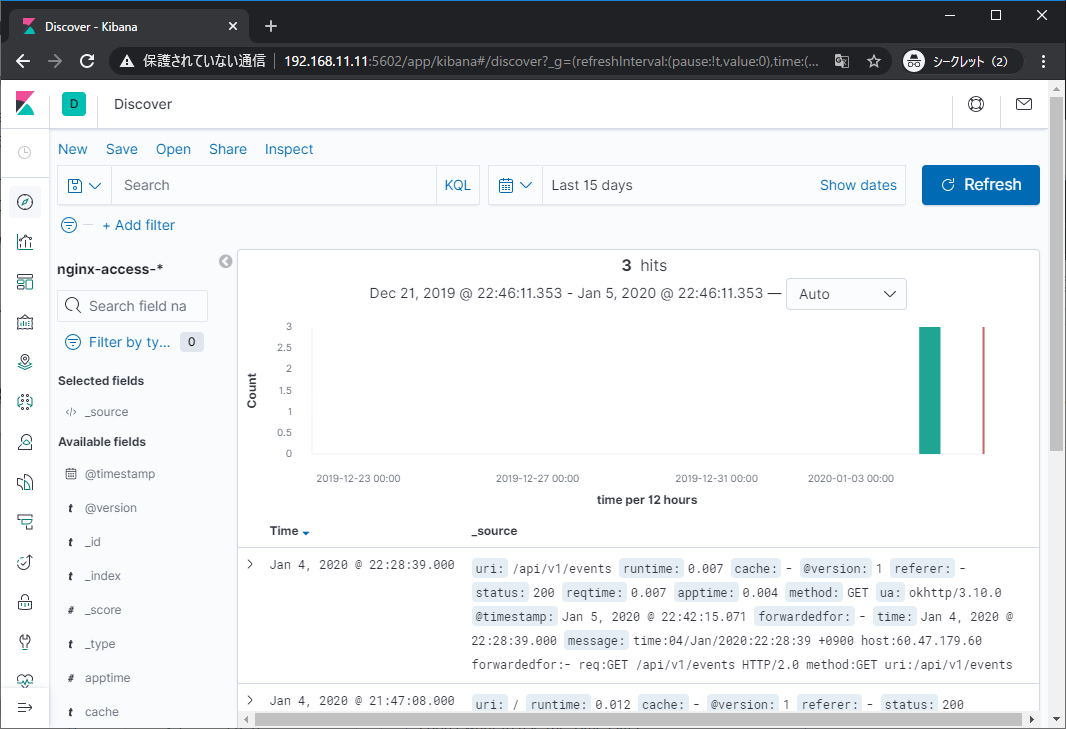
インデックスパターンを追加したら再びDiscoverタブを開き、ログの日付が収まるように表示範囲を選択すると以下のようにログが表示されます。
別のデータを投入し、新規にインデックスパターンを作成する場合はManagement -> Index Patterns -> Create index patternから同様の手順を踏めばOKです。
次回はいよいよログを可視化していきます。