かれこれCirclesearchを公開してから丸3年が経過しているんですが、公開してからというものパフォーマンスをしっかり調べたことが無かったので調べてみることにしました。
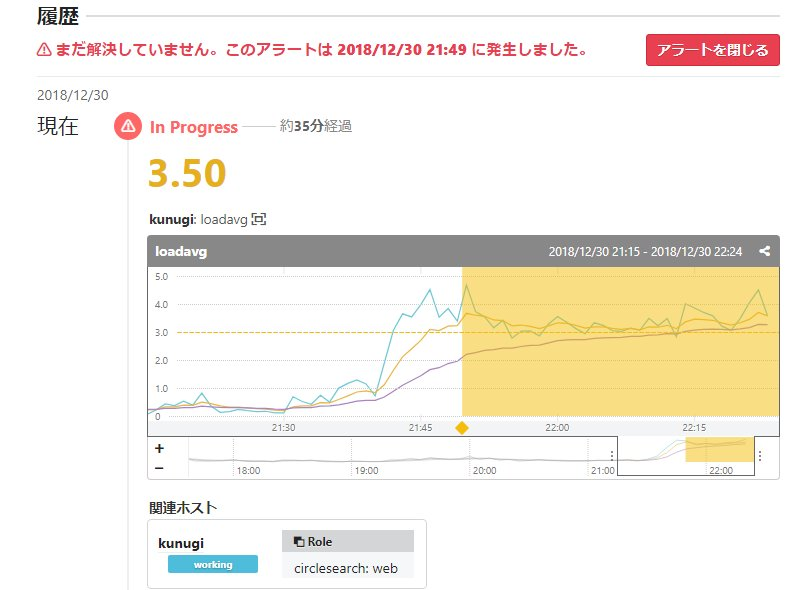
運用しているサーバには一応死活監視としてMackerelエージェントを導入していて、アクセスが集中していた時間が存在していることはわかっていた(画像参照)んですが、一歩踏み込んだ定量的な評価ができていませんでした。
以前の記事で紹介した通りログを収集する基盤ができたので、これを利用して当時の状況を掘り下げて確認したいと思います。
ActiveJobログを取り込む
Logstashの設定
今回はこれまでに紹介したログに加えRailsのアプリケーションログからActiveJobのレコードを抽出します。
実際のログは以下のような感じです。
I, [2020-01-26T15:59:29.031487 #392] INFO -- : [1297ce54-9f7c-46de-8067-3ec218bc8b32] [ActiveJob] Enqueued UserUpdateJob (Job ID: 3c465da6-04ff-418c-836c-c336844ed7ed) to Sidekiq(updating_accounts) with arguments: 392725346
I, [2020-01-26T15:59:29.032357 #311] INFO -- : [ActiveJob] [UserUpdateJob] [3c465da6-04ff-418c-836c-c336844ed7ed] Performing UserUpdateJob (Job ID: 3c465da6-04ff-418c-836c-c336844ed7ed) from Sidekiq(updating_accounts) enqueued at 2020-01-26T06:59:29Z with arguments: 392725346
I, [2020-01-26T15:59:34.023975 #311] INFO -- : [ActiveJob] [UserUpdateJob] [3c465da6-04ff-418c-836c-c336844ed7ed] Performed UserUpdateJob (Job ID: 3c465da6-04ff-418c-836c-c336844ed7ed) from Sidekiq(updating_accounts) in 4991.46msこれらのレコードを見てみると、Enqueued UserUpdateJobの行とPerforming UserUpdateJob, Performed UserUpdateJobの行で微妙に構成が異なっています。
この2パターンにマッチするように正規表現を引っかけていきます。
まず前者はこう
(?<state>Enqueued) %{NOTSPACE:job} \(Job ID: %{NOTSPACE:jid}\) to .+\(%{NOTSPACE:queue}\) with arguments: %{INT:arg}後者はこう
\[%{NOTSPACE:job}\] \[%{NOTSPACE:jid}\] (?<state>Performing|Performed)(.*\(%{NOTSPACE:queue}\) in %{NUMBER:duration}ms)?今回はジョブのIDを使ってレコードを集約するので、これをjidとして拾えるようにしておきます。
またPerforming, Performedの行はそれぞれ内容が異なるので、どちらの行であるかをstateとして引っかけつつ、実行時間も拾うようにしました。
最後にこれを合体させ、時刻と合わせてマッチさせるようにするとこんな感じに。
grok {
match => [ "message", "\[%{TIMESTAMP_ISO8601:time} #%{INT:pid}\] +%{LOGLEVEL:loglevel} -- : .*?\[ActiveJob\] ((?<state>Enqueued) %{NOTSPACE:job} \(Job ID: %{NOTSPACE:jid}\) to .+\(%{NOTSPACE:queue}\) with arguments: %{INT:arg}|\[%{NOTSPACE:job}\] \[%{NOTSPACE:jid}\] (?<state>Performing|Performed)(.*\(%{NOTSPACE:queue}\) in %{NUMBER:duration}ms)?)" ]
}最終的な設定ファイルは以下のようになりました。
input {
stdin {}
}
filter {
# remove ANSI color sequences
mutate {
gsub => ["message", "\x1B\[([0-9]{1,2}(;[0-9]{1,2})?)?[m|K]", ""]
}
grok {
match => [ "message", "\[%{TIMESTAMP_ISO8601:time} #%{INT:pid}\] +%{LOGLEVEL:loglevel} -- : .*?\[ActiveJob\] ((?<state>Enqueued) %{NOTSPACE:job} \(Job ID: %{NOTSPACE:jid}\) to .+\(%{NOTSPACE:queue}\) with arguments: %{INT:arg}|\[%{NOTSPACE:job}\] \[%{NOTSPACE:jid}\] (?<state>Performing|Performed)(.*\(%{NOTSPACE:queue}\) in %{NUMBER:duration}ms)?)" ]
}
if "_grokparsefailure" in [tags] {
drop { } # skip if parsing failed
}
date {
match => [ "time", "ISO8601" ]
target => "time"
timezone => "Asia/Tokyo"
}
if [state] == "Enqueued" {
aggregate {
task_id => "%{jid}"
code => "map['enqueued_at'] = event.get('time')"
}
drop { }
}
if [state] == "Performing" {
aggregate {
task_id => "%{jid}"
code => "map['started_at'] = event.get('time')"
}
drop { }
}
if [state] == "Performed" {
aggregate {
task_id => "%{jid}"
code => "event.set('enqueued_at', map['enqueued_at']); event.set('started_at', map['started_at'])"
end_of_task => true
}
mutate {
rename => {
"time" => "finished_at"
}
}
mutate {
remove_field => [ "state" ]
convert => {
"duration" => "float"
}
copy => {
"finished_at" => "@timestamp"
}
}
ruby {
code => "event.set('duration', (event.get('duration') / 1000).round(1))"
}
mutate {
remove_field => [ "host" ]
}
}
fingerprint {
source => "message"
target => "[@metadata][fingerprint]"
method => "MD5"
}
ruby {
code => "event.set('[@metadata][tsprefix]', event.get('@timestamp').to_i.to_s(16))"
}
}
output {
stdout { codec => rubydebug { metadata => true } }
elasticsearch {
hosts => ["localhost:9200"]
index => "circlesearch-production-activejob-%{+YYYY.MM}"
document_id => "%{[@metadata][tsprefix]}%{[@metadata][fingerprint]}"
}
}タイムゾーンがログ側で明示的に記録されていないのでここで記述しています。
Scripted Fieldを作る
Logstashを実行してElasticsearchにデータを取り込みますが、ジョブの実行時間に対してジョブの待機時間は記録されていません。そこで、Kibana上でScripted Fieldを使ってキューイングされた時刻とジョブ開始時刻から待機時間を算出します。
インデックスパターンを作成したらScripted FieldからAdd scripted fieldをクリックして以下のようにpainlessスクリプトを記述します。
if (!doc['enqueued_at'].empty) {
return Math.max((doc['started_at'].value.getMillis() - doc['enqueued_at'].value.getMillis()) / 1000.0, 0)
}いざ可視化
ジョブの実行数
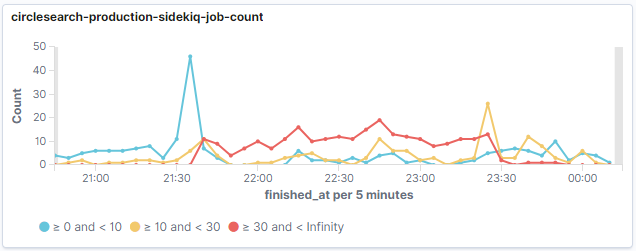
以前の記事と同じグラフですが、アクセスが集中した時間帯に実行時間30秒以上を示すラインが伸びており、全体のスループットが低下していることがわかります。
ジョブの待機時間
続いてジョブがキューに入ってから実行開始までの待機時間を見てみます。
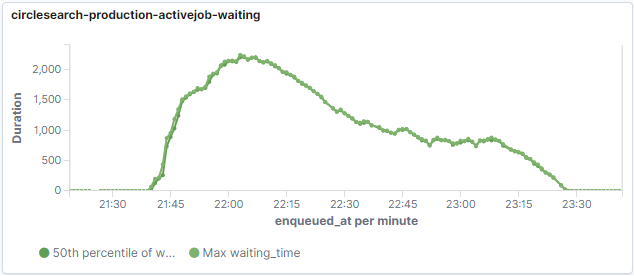
……これはまずい。
最大値にあわせて中央値も表示してみましたが、ほぼ最大値に張り付いているのでほとんどのジョブがグラフの通りの時間待機していたことになります。待機時間はキュー内のジョブの実行状況に依存するので当然といえばその通りですが、一番ひどいときで2000秒ということは30分近く待たされる結果に……。
ジョブの実行時間
個々のジョブの実行時間についても見てみましたが、案の定パフォーマンスが著しく落ちています。
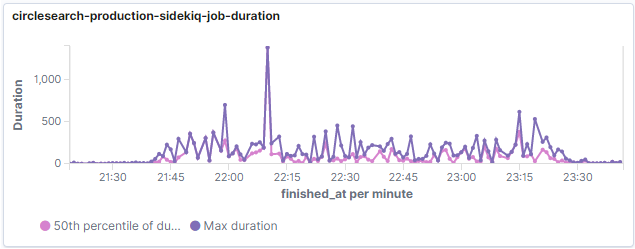
ここで特にアクセスが集中した時間帯に対して、平時との違いを比較してみることにしました。
まずElasticsearchに投入したデータからユーザIDと各ジョブの最大実行時間を取得し、別途Twitter APIを用いてユーザIDからフォローユーザ数(すなわち更新対象ユーザ数)とジョブ実行時間のペアに変換してプロットしてみます。
Elasticsearchからデータを取得して変換するスクリプトがこちら。
ページングは結構適当です。
require 'open-uri'
require 'twitter'
token = {
consumer_key: '',
consumer_secret: '',
access_token: '',
access_token_secret: ''
}
rest = Twitter::REST::Client.new(token)
uri = URI.parse('http://localhost:9200/circlesearch-production-activejob-*/_search')
records = []
page = 0
size = 100
while true
req = Net::HTTP::Get.new(uri, 'Content-Type' => 'application/json')
req.body = JSON.pretty_generate({
query: {
bool: {
must: {
match: {
job: 'UserUpdateJob',
},
},
filter: {
range: { enqueued_at: { gte: '2019-12-28T00:00:00+0900', lte: '2019-12-31T00:00:00+0900' } }
}
}
},
_source: [ 'args.user_id', 'duration' ],
from: size * page,
size: size
})
res = Net::HTTP.start(uri.host, uri.port) do |http|
http.request(req)
end
docs = JSON.parse(res.body)['hits']
records.push(*docs['hits'])
page += 1
break if page * size > docs['total']['value']
end
h = records.each_with_object(Hash.new(0)) do |r, h|
d = r['_source']['duration']
uid = r['_source']['args']['user_id']
h[uid] = [d, h[uid]].max
end
rest.users(h.keys).each { |u| puts "#{u.friends_count} #{h[u.id]}" }この結果を期間を分けたうえで散布図としてプロットしてみます。
まず12月頭から12月28日までのデータによるものがこちら。
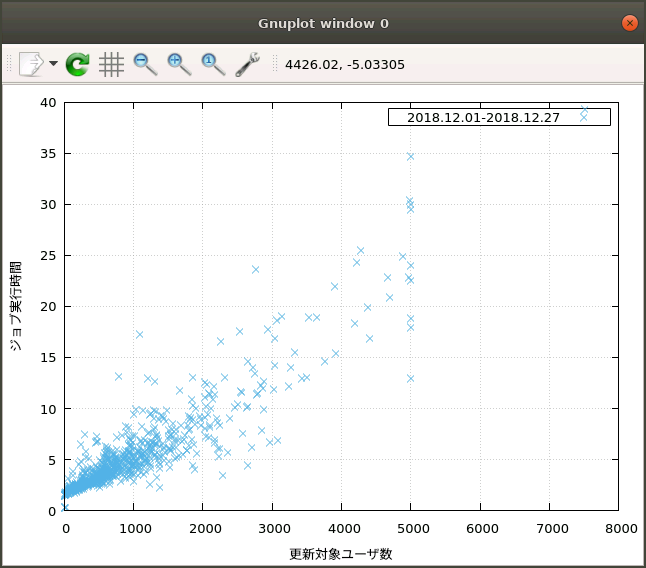
おおよそ更新対象ユーザ数に比例してジョブ実行時間が増加していることがわかります。
そして12月29日から31日までのデータを重ねたものがこちら。
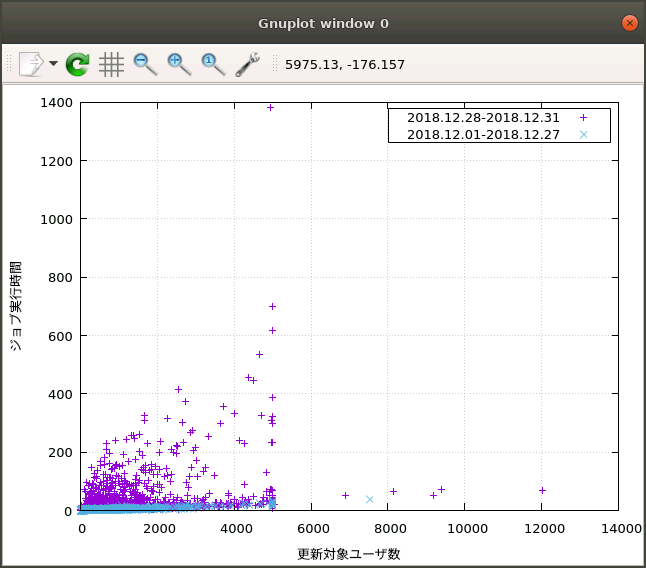
明らかに実行時間が爆発してしまっている様子がわかります。
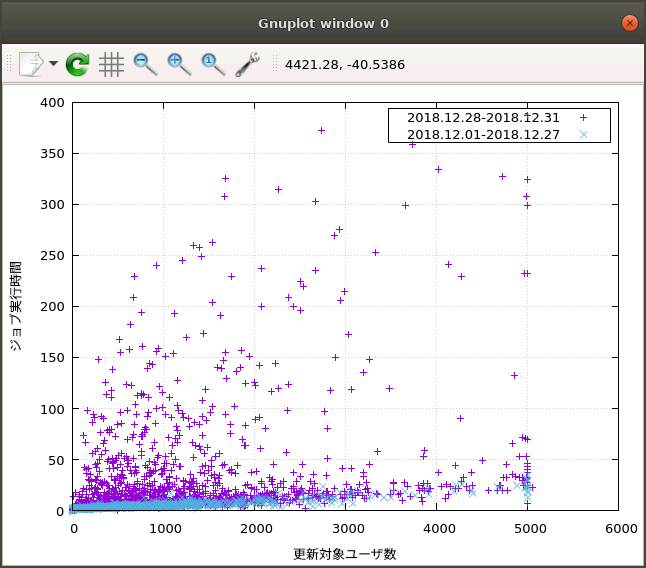
時間軸方向のばらつきはあるものの、平時と比べると数倍どころか1桁2桁単位で実行時間が増大していることが明らかになりました。
原因
あまりサーバのメモリに余裕がなかったというのはあるんですが、何を考えていたのかジョブ実行時にすべてのデータをメモリ上に展開してしまっていることと、ジョブキューの実行数が大きめになっていたことが原因であると考えています。
大きめのトラフィックをしっかり捌いていたことがなかったので気づくのが遅くなりまってしまいました。
まとめ
この結果を受けて改善できるところを早めに直していきたいと思います。
今回はたまたまとっておいたバックアップの中にアクセス集中時のログも残っていたので、ログをとっておいて損はないことを実感しました。